Accelerating by Idling
How Speculative Delays Improve Performance of Message-Oriented Systems
August 2017
Can the performance of a message-oriented system be improved by adding periods of idle execution?









Context switch
A period of time required for the scheduler to switch the CPU from one actor to another.






Spinning before a context switch potentially improves performance.
But not always.


An actor should delay the context switch only if it is likely that a message will arrive.
1. When should an actor spin?
2. How long should an actor spin?
There exists a simple upper bound.



d (delay) < c (context switch)
How to pick a delay in [0, c>?
Assume that P is the probability that a message arrives after some time d.





The actor also needs to occasionally sample P, i.e. spin several times to determine P.
We will assume that the actor samples with some probability φ.








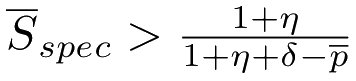
Conclusion: given a probability p that a message arrives after δ, an actor should delay the context switch if:
δ < p
Delay sampling
Before the context switch:
1. With probability φ << 1, spin c time.
2. Record the message arrival times ti.
3. After collecting N samples, group the delay times into M buckets, and report the pairs δi, pi.

Speculative idling
Before a context switch:
1. Take the last reported M pairs δi, pi.
2. Pick the pair with minimal δi - pi.
3. If the difference is positive, wait δi time before context switching.
Sample size n?
For 95% confidence that the sampled probability P lies within 15% of its true value, we need n = 43.
For a sampling probability φ = 0.01, the expected number of activations per actor is ~4300.
But, actors are short-lived.
In many applications, most actors are not activated 4300 times.
How to obtain a sample more quickly?
Greedy sampling
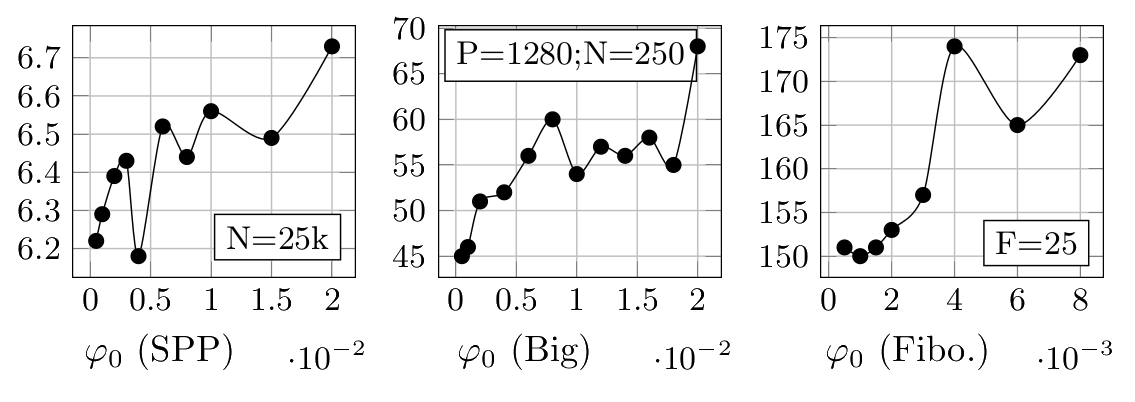
Always set the sampling frequency φ to a value proportionate to the running best probability pi.
Intuition: If the message arrival probability P is high, then more frequent sampling is not detrimental.
I.e. an actor spends more time sampling, but it is likely that messages will arrive during sampling, saving a context switch.

If the message arrival probability P is low, then less frequent sampling is not detrimental.
I.e. it might take a long time to collect the sample, but it's unlikely that it will help anyway.

Greedy sampling
Initially, set the sampling frequency to some small value φ0. After each sampling, set the frequency to:
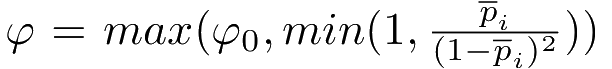
Greedy sampling
Expected number of messages before obtaining a sample:
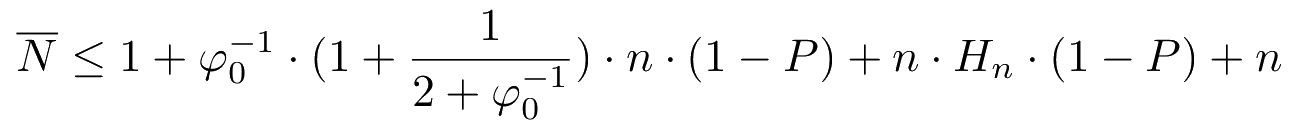
Greedy sampling
Lower bound on speedup:
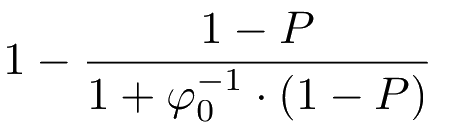
Benchmarks:
Savina Actor Suite
Shams and Sarkar, AGERE 2014

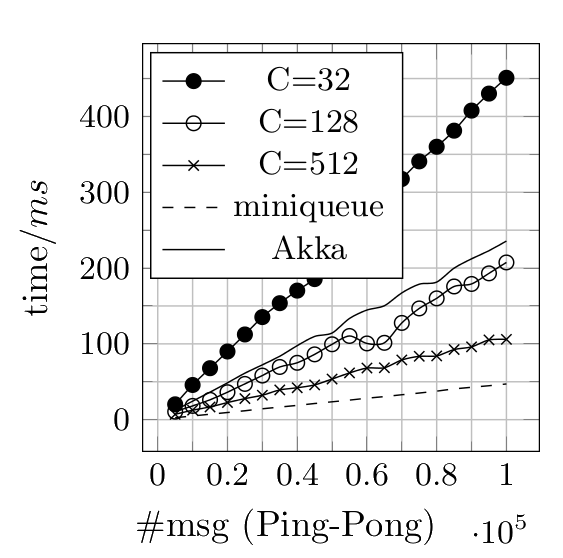
Ping-Pong

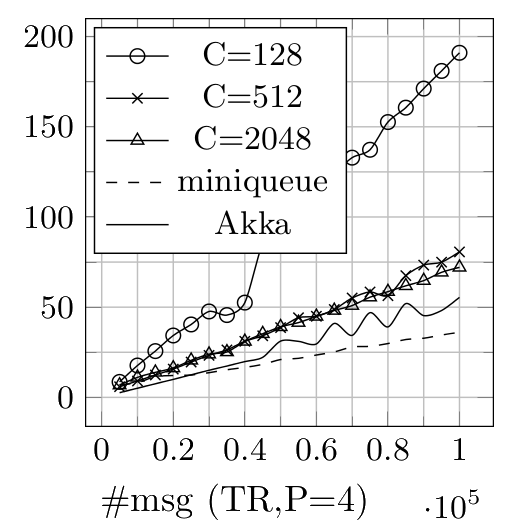
Thread Ring

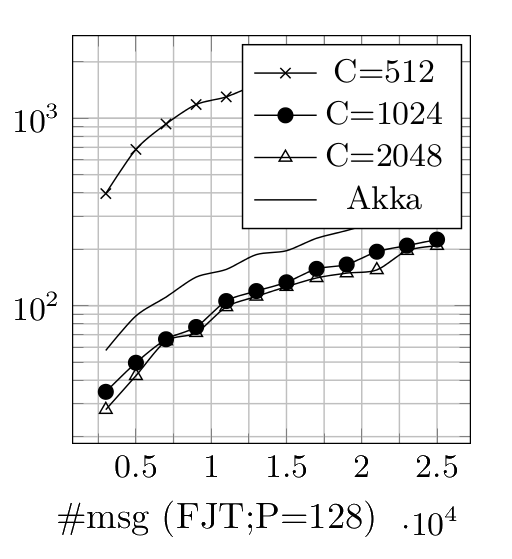
Fork Join Throughput